Policy Gradient
Policy Gradient的核心思想
其实 Policy Gradient 的核心思想非常简单,就是找一个函数π,这个函数π能够根据现在环境的状态(state)来产生接下来要采取的行动或者动作(action)。即π(state)→action。
函数π其实可以看成是一个模型,那么想在无数次尝试中寻找出能让 Agent 尽量拿高分的模型应该怎样来找呢?我相信您应该猜到了!没错!就是神经网络!
我们可以将游戏画面传给神经网络作为输入,然后神经网络预测一下当前游戏画面下,下一步动作的概率分布。
细心的您可能会发现,如果每次取概率最高的动作作为下一步的动作,那不就成分类了么。其实 Policy Gradient 的并不是每次都选取概率最高的动作,而是根据动作的概率分布进行采样。也就是说就算我预测出来的向上挪的概率为 80% ,也不一定会向上挪。
那么为什么采样而不是直接选取概率最大的呢?因为这样很有灵性。可以想象一下,我们和别人下棋的时候,如果一直按照套路来下,那么对手很可能能够猜到我们下一步棋会怎么走,从而占据主动。如果我们时不时地不按套路出牌,但是这种不按套路的动作不会降低太多对于我们能够赢下这一局棋的几率。那么对手很可能会不知所措,主动权就掌握在我们手里。就像《天龙八部》中虚竹大破珍珑棋局时一样,可能有灵性一点,会有意想不到的效果。
Policy Gradient 的原理
现在已经知道 Policy Gradient 是通过神经网络来训练模型,该模型需要根据环境状态来预测出下一步动作的概率分布,并根据这个概率分布进行采样,将采样到的动作作为下一步的动作。
那么会有一个灵魂拷问,就是怎样来鉴定我的神经网络是好还是坏呢?很显然,当然是赢的越多越好了!所以我们不妨假设,让计算机玩 10 把乒乓球游戏,那么可能会有这样的一个统计结果。
那么怎样评价这 10 把游戏打的好还是不好呢?也很明细,把 10 把游戏的所有反馈全部都加起来就好了。如果把这些反馈的和称为总反馈(总得分),那么就有总反馈(总得分)=第1把反馈1+第1把反馈2+...+第10把反馈m。也就是说总反馈越高越好。
说到这,有一个问题需要弄清楚:假设总共玩了 100 把,每 10 把计算一次总反馈,那么这 10 次的总反馈会不会是一模一样的呢?其实仔细想想会发现不会一摸一样,因为:
- 游戏的状态实时在变,所以环境状态不可能一直是一样的。
- 动作是从一个概率分布中采样出来的。
既然总反馈一直会变,那么我们可以尝试换一种思路,即计算总反馈的期望,即总反馈的期望越高越好。那这个期望怎么算呢?
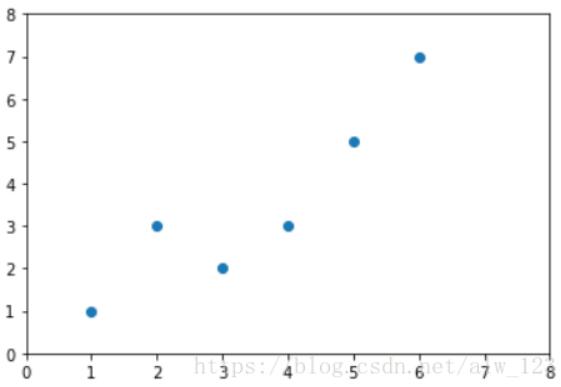
首先我们可以将每一把游戏看成一个游戏序列(状态1->动作1->反馈1->状态2->动作2->反馈2 ... 状态N->动作N->反馈N)。那么每一个游戏序列(即每一把游戏)的反馈=反馈1+反馈2+...+反馈N。因此,若假设R(τ)表示游戏序列τ的反馈,则有:R(τ)=∑n=1Nτn。
如果我们把整个乒乓球游戏所有可能出现的状态,动作,反馈组合起来看成是玩了 N(N很大很大) 把游戏,就会有 N 个游戏序列(游戏序列1,游戏序列2,游戏序列3, ... , 游戏序列N)。那么我们在玩游戏时所得到的游戏序列实际上就是从这 N 个游戏序列中采样得到的。
所以我们游戏的总的反馈期望Rθ可表示为:Rθ=∑τR(τ)P(τ∣θ)。这个公式看起来复杂,其实不难理解。
假设我们玩了 10 把游戏,就相当于得到了 10 个游戏序列[τ1,τ2,...,τ10]。这 10 个游戏序列就相当于从 P 中采样了 10 次τ。所以总反馈期望Rθ又可以近似的表示为:
Rθ≈N1∑n=1NR(τn)
由于Rθ的值越大越好,所以我们可以使用梯度上升的方式来更新θ。所以就有如下数学推导:
又由于:
Rθ=∑τR(τ)P(τ∣θ)≈N1∑n=1NR(τn)
所以就有:
∇Rθ≈N1∑n=1NR(τn)∇logP(τn∣θ)
您会发现∑n=1NR(τn)很好算,只要把反馈全部加起来就完事了,难算的是∇logP(τn∣θ)。所以我们来看一下∇logP(τn∣θ)应该怎么算。
由于一个游戏序列τ是由多个状态,动作,反馈构成的,即:
τ={s1,a1,r1,s2,a2,r2,...,sT,aT,rT}
所以:
P(τ∣θ)=P(s1)P(a1∣s1,θ)P(r1,s2∣s1,a1)P(a2∣s2,θ)P(r2,s3∣s2,a2)...
稍微整理一下可知:
P(τ∣θ)=P(s1)∏t=1TP(at∣st,θ)P(τt,st+1∣st,at)
然后两边取log会得到:
logP(τ∣θ)=∑t=1T∇logP(at∣st,θ)
P(at∣st,θ)其实就是我们神经网络根据环境状态预测出来的下一步的动作概率分布。
OK,到这里,Policy Gradient 的数学推导全部推导完毕了。我们不妨用一张图来总结一下 Policy Gradient 的算法流程。流程如下: